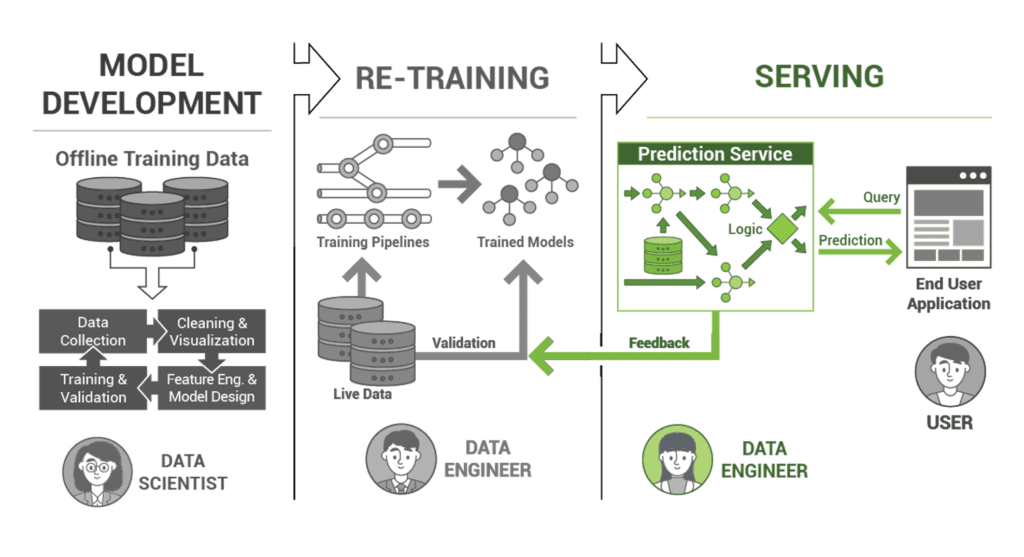
Imagine spending hours crafting a beautiful painting, only to realize you don’t have the right frame to display it. Similarly, in the realm of machine learning, once a model is trained, it needs the right ‘frame’ or mechanism to deliver its predictions to the world. This is where the serving layer comes into play. This article aims to demystify the intricate process of developing a serving layer for a machine learning pipeline by exploring the best practices and common pitfalls that can trip up even seasoned experts.
The Art of Managing the Serving Layer: Best Practices for Excellence
Serving with efficiency
No matter how exquisite the dish, if it doesn’t arrive on time or in the right quantity, it loses its charm. A prompt serving layer results in quick predictions, ensuring that users are not left waiting and are more satisfied with the overall experience.
- Netflix’s initial global foray in 2012 faced challenges. The platform experienced hiccups due to insufficient scalability. However, upon transitioning to a robust, scalable infrastructure, it gracefully caters to millions of binge-watchers worldwide.
Periodically update and retrain your model
A recipe might need tweaking based on the changing tastes of your audience. Likewise, a model requires periodic retraining to stay relevant. The digital realm is dynamic. By regularly retraining and updating your model, you prevent model degradation over time, and you ensure its predictions remain in line with evolving data patterns. This leads to the improved performance of the machine learning model.
- Take Google’s PageRank algorithm, the backbone of their search engine. To stay on top, Google doesn’t rest on its laurels. The algorithm is consistently retrained with fresh data, ensuring that its search results remain relevant and accurate.
Constant monitoring & anomaly detection
The chef periodically tastes the dish to ensure it’s on track. Similarly, monitoring the model provides continuous feedback on its performance. Regularly monitoring your model acts as an early detection system for potential issues, ensuring that you maintain a high standard of prediction accuracy. It directly influences user satisfaction with the system.
- Spotify, the music streaming giant, is always listening. By implementing real-time monitoring for its recommendation system, Spotify ensures that any blips in song suggestions are corrected swiftly, leading to happier users lost in their favorite tunes.
Tools tailored for serving
Just as a chef picks the right tools for the task, choosing purpose-built tools for your serving layer can greatly enhance its performance. Platforms like TensorFlow Serving, Kubeflow, and Seldon are designed with the nuances of machine learning in mind. They simplify deployment, boost reliability, and streamline updates and versioning.
- Etsy, the beloved global marketplace for unique items, understands the importance of using the right tools. To scale and manage its machine learning models with finesse, Etsy relies on the powerful Kubernetes platform.
Navigating the Waters: Challenges in Developing the Serving Layer
The world of machine learning is as enchanting as navigating a vast ocean on a sailing ship. As with the great explorers of yore, we, too, are confronted by potential challenges and dangers. However, forewarned is forearmed. We’ll explore the lurking challenges in developing and monitoring the serving layer of a machine learning system.
Inadequate version control of models and data
Version control’s importance cannot be overstated. Just as sailors relied on accurate navigation charts, so do we need a correct version of data and models. Without precise version control, it’s easy to lose track of which model or data version you’re using. This leads to issues with reproducibility and potential system failures.
- Imagine a hospital dependent on a tool for predicting disease outbreaks. An unexpected model failure showed it had been trained on an older data version. The consequences? Dire misestimations of resource requirements.
Fix: The way forward is clear! Adopt a robust version control system that caters to the unique demands of machine learning, tracking concurrent changes seamlessly.
Inability to handle invariant features and changes in the data distribution
This mistake can lead to inaccurate predictions and a degradation in the performance of machine learning models. Our models need to be prepared. Many machine learning models work under the assumption that future data will look a lot like past data. When this assumption breaks, performance can plummet.
- A road traffic prediction model, fine-tuned for years of standard data, faced unprecedented challenges during the unforeseen COVID-19 lockdowns, leading to grossly inaccurate predictions.
Fix: The solution lies in agility! Frequently retrain models and embed systems that alert you to major shifts in data distribution.
Not designing for scalability and resilience
An unprepared ship is at the mercy of the vast ocean. Similarly, systems not designed for scalability can easily get overwhelmed. As user demands increase, an unscalable system falters, unable to handle the onslaught of data.
- A budding e-commerce platform launched a recommendation system. As its user base exploded, so did its system’s response times, leading to a detrimental user experience and frequent crashes.
Fix: Prepare for growth from day one! Implement architectures that can scale up effortlessly, ensuring your system remains agile and responsive.
Not monitoring and updating the model regularly
Like a ship left adrift, a model not regularly updated loses its way. Over time, unmonitored models can drift away from optimal performance, gradually delivering subpar predictions.
- Think about an AI-driven chatbot designed to help users who started doling out puzzling responses. Investigations revealed an outdated model at the heart of the problem.
Fix: Set a course for continual improvement! A regular review schedule, coupled with retraining sessions, ensures your model remains sharp and relevant.
Jamie’s Machine Learning Adventure: Serving Tunes to the School
In the bustling corridors of Northwood High, Jamie, a senior with a penchant for tech, was known as the “music predictor.” It wasn’t a psychic ability but rather a machine learning model Jamie had developed that could predict the popularity of a song based on its features. The model was Jamie’s pride and joy, but there was one problem: how could Jamie share this cool tool with friends and teachers?
One sunny afternoon, while lounging in the school’s courtyard, Jamie had an idea. Why not create a simple website where anyone could input song features and get instant predictions? The concept of a “serving layer” was born.
Determined, Jamie started with Flask, a lightweight web framework. It was perfect for Jamie’s needs, allowing the model to spit out predictions in real-time. The first user was Alex, Jamie’s best friend and a budding musician. Alex was thrilled! The tool gave instant feedback, allowing him to tweak his compositions on the fly.
But as word spread, Jamie noticed a challenge. Music trends evolve, and the model needed to stay updated. So, Jamie set a reminder on the school computer to retrain the model every month with fresh song data. This foresight paid off when the school’s annual music fest rolled around. The model’s predictions were spot on, helping many students adjust their performances.
However, popularity came with its own set of problems. One day, after a local music blogger mentioned Jamie’s tool, there was a sudden spike in users. The server was overwhelmed! Jamie realized the importance of constant monitoring. A logging system was quickly put in place, alerting Jamie if predictions took too long or if there was an unexpected surge in requests.
The real game-changer was when Jamie discovered TensorFlow Serving. It was like magic! Designed specifically for serving machine learning models, it simplified deployment and could handle the school’s traffic with ease.
Yet, every adventure has its dragons. As Jamie made improvements to the model, ensuring the website used the latest version became a maze. Version control, a term Jamie had only heard in passing, became the hero of the day. With it, Jamie could easily track and manage different model versions.
The school year ended, but Jamie’s serving layer legacy lived on. It wasn’t just about predicting song popularity; it was a testament to Jamie’s determination and the magic of making machine learning accessible to all.