I want you to imagine for a moment that you’re in an enormous, sprawling library. Picture the rows and rows of books, each one filled with stories, information, and ideas, each one a world unto itself. But there’s one catch: there are no titles, no authors, no table of contents, and no indices in these books. Now, if I were to ask you to find a book on a specific topic – say, the history of Renaissance art – where would you begin? How much time would you have to spend flipping through each book, hunting for the exact information you need?😥
Well, in many ways, the digital world we’re living in is like that vast library. But thankfully, we have something that makes navigating this world of information more manageable. And that something is metadata.
So, you might be wondering, “What is metadata?” Essentially, metadata is data about data. It’s the titles, authors, and table of contents for our digital library. It’s the details that tell us what a file is, when it was created, who created it, what’s in it, and so much more. It’s the secret ingredient that helps us make sense of the vast digital universe we navigate every day, even if we’re not always aware of it.
Every time you Google a question and find an answer, every time you search for a file on your computer, every time you sort your music library 🎵 by artist, album, or year, you’re using metadata. In fact, if you’ve ever cursed your computer for not being able to find a document you know you saved somewhere, you’ve encountered the frustration of a world without sufficient metadata.
Over the next few minutes, I’ll guide you on a journey to understand the significance of metadata. How it allows us to explore the vast depths of information at our fingertips, its role in our everyday lives, and how we can leverage it effectively to enhance our understanding of the world around us. So buckle up, and let’s dive into the unseen, unsung hero of our digital universe: metadata.
Why Understanding Your Data is Important
Let’s say you’re running for student council, and you want to know what issues are most important to your classmates. You might conduct a survey, asking students about their concerns. The survey results are your data. But to make sense of this data, you need metadata: what grade is each student in? What clubs do they belong to? How many times have they been to the school nurse? These details will help you focus your campaign on the issues that really matter to your voters.
This is just like how in data analysis.
- Understanding the contents helps in selecting relevant features or variables for analysis. You can identify variables of interest and their potential relationships, enabling targeted investigations like the relationship between grade level and concerns.
- Understanding the contents (e.g., data types) is important for selecting appropriate analysis techniques and performing data manipulations accurately.
- Understanding the contents helps you explore the patterns, relationships, and distributions within the data.
- Understanding the contents aids in the interpretation of analysis results. For instance, let’s say the school cafeteria wants to introduce new meals, and they conduct a taste test. If they report that a meal had an average rating of 8, it would make a big difference if we knew whether the ratings were out of 10 or 100!
Using Metadata to Explore Your Data
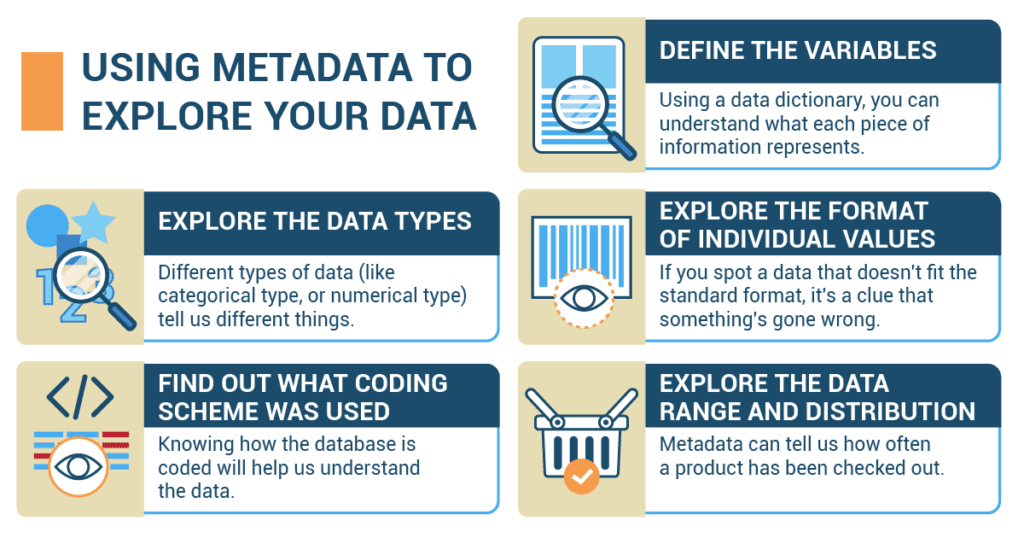
Now, let’s dive into how you can use metadata. Let’s imagine your school has a database of all the books in its library. The data includes information like the book title, author, genre, and the number of times it’s been checked out.
- Define the variables: Use a data dictionary to get a description of each variable, including what they represent and their units of measurement. For instance, knowing that ‘checkouts’ means the number of times the book has been borrowed can help you see which books are popular. These descriptions can provide insights into what each variable represents, its purpose, and its expected data type.
- Here are some common ways in which metadata defines variables:
- Variable name: Metadata often includes the name or label assigned to a variable, which serves as its identifier in the dataset or system.
- Data type: Metadata specifies the data type of a variable, such as numeric, categorical, text, date, or boolean. This information helps us understand the nature of the values the variable can hold.
- Description: Metadata provides a description or brief explanation of the variable, highlighting its purpose, meaning, or significance. This description aids in understanding the variable’s role in the dataset or system.
- Units of measurement: For variables that represent physical quantities (e.g., length, weight, time), metadata may include the units of measurement applied to the variable values. This information ensures proper interpretation and comparison of the data.
- Valid value range: Metadata may define the valid range or acceptable values for a variable. It sets boundaries or constraints on what values are considered valid or meaningful. This helps identify data quality issues or anomalies.
- Relationships or dependencies: Metadata may describe relationships or dependencies between variables. It can specify if a variable is linked to other variables through hierarchical, temporal, or other types of relationships.
- Source or origin: Metadata may indicate the source or origin of a variable, such as the data collection instrument, survey, database, or system from which the variable is obtained. This information aids in tracking the data lineage and assessing data quality.
- Contextual information: Metadata may provide additional contextual information about a variable, such as its intended use, historical background, legal or ethical considerations, or any specific assumptions or limitations associated with the variable.
- Here are some common ways in which metadata defines variables:
- Explore the data types: Different types of data tell us different things. Use metadata to get information on the data types (integer, string, float, boolean, etc.) in your dataset. A book’s genre (like Mystery, Fantasy, or Biography) is a categorical type of data, while the number of times it’s been checked out is a numerical type.
- Explore the format of individual values: Metadata may specify the length or format of fields, particularly for string variables. For example, A book’s ISBN number has a specific format. If you spot an ISBN number that doesn’t fit this format, it’s a clue that something’s gone wrong.
- Find out what coding scheme was used for categorical data and missing data. A data coding scheme, also known as a codebook or coding system, is a set of rules or guidelines used to assign codes to represent specific categories or values for data elements. It provides a standardized method for encoding or classifying data, making it easier to analyze and interpret information consistently. This information is valuable in understanding any limitations or restrictions on the data, such as character limits or specific formatting requirements. In our library database, genres might be coded as numbers (like 1 for Mystery, 2 for Fantasy). Knowing this helps us understand the data.
- Explore the data range and distribution: It describes the range of values that variables can take and provides insights into the distribution or spread of those values. Metadata can tell us how often a book has been checked out. If one book was checked out 500 times last month while most others were only checked out once or twice, we might have a super popular book on our hands!
Best Practices and Watch-outs with Metadata
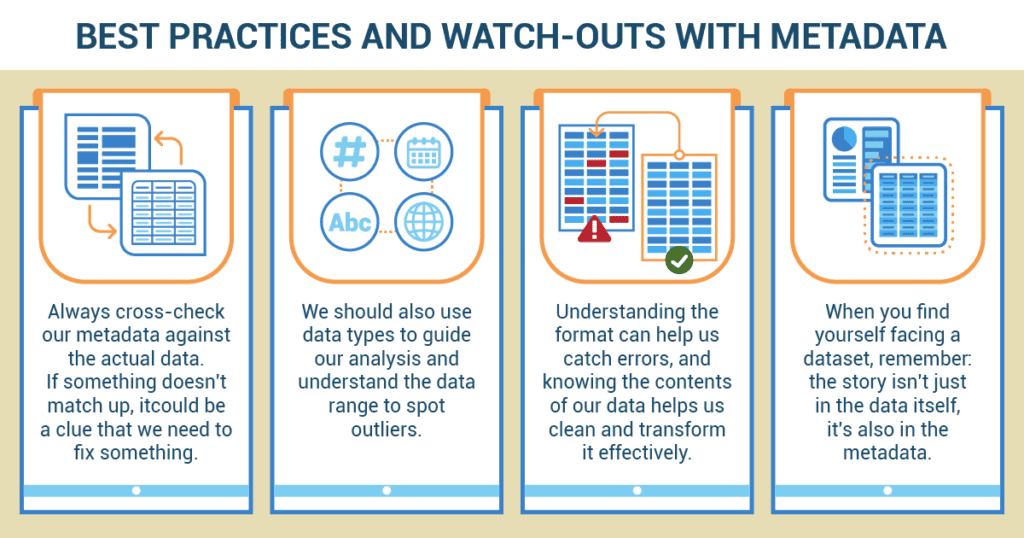
- Validate the metadata by cross-checking it against the actual data. Ensure that the data values, formats, and patterns align with the information provided in the metadata.
- Use the data types to help you determine the kinds of operations and analysis to perform on each column.
- Use the data range to identify and correct outliers. Understanding the context helps to distinguish between outliers that are data errors and those that represent genuine high or low values.
- Use the formatting standards to identify and correct formatting errors. If metadata indicates a column of dates that should follow a particular format, and you find dates that do not match this format, this indicates an error that should be corrected.
- Use your understanding of the data contents to guide data cleaning and transformation. Knowledge about the contents can guide your decisions about how to handle missing data and whether certain variables need to be transformed (like applying a logarithm to highly skewed data).
Hashtag Henry: Harnessing the Power of Metadata
 Henry had always been a whiz at using social media. His posts were consistently met with hundreds of likes, shares, and comments. Yet, he wondered if there was more he could do to connect with his followers. With a student council election coming up, he decided to delve deeper into his social media data, hoping to glean insights to aid his campaign.
Henry had always been a whiz at using social media. His posts were consistently met with hundreds of likes, shares, and comments. Yet, he wondered if there was more he could do to connect with his followers. With a student council election coming up, he decided to delve deeper into his social media data, hoping to glean insights to aid his campaign.
Within his social media profiles, he found a treasure trove of data: likes, shares, comments, followers, and more. But it was the metadata that truly intrigued Henry. He noticed that beyond the number of likes or shares, there was data about data: the date and time of his posts, the type of content he shared, and even the hashtags he used. This metadata, he realized, held the key to understanding his social media reach.
Among the metadata, Henry noticed two particular variables: post time and post type (photo, text, or video). Curious, he started examining the relationship between these variables and his engagement levels. Were his photo posts more popular than his videos? Did his posts at 3 PM get more likes than those at 8 PM? Using a simple spreadsheet and some basic statistical tools, he started to explore these relationships.
The data types in the metadata were also of interest to him. His posts’ content was recorded as text strings, but the time of posting was a timestamp, and the number of likes and shares were integers. Recognizing these different data types helped Henry determine the kind of analysis he could perform.
Additionally, the metadata provided him with information about the coding scheme for his post types. Each post was tagged with a numerical code: 1 for text, 2 for photo, and 3 for video. Understanding this coding scheme allowed Henry to perform a detailed analysis of his post types.
When Henry examined the range of his metadata, he noticed something unusual. One of his video posts had only 2 views but had received 200 likes. This discrepancy led him to realize there had been a glitch in the view counter for that particular post. Without the metadata, this error might have skewed his analysis.
As he delved deeper into the metadata, he started to see patterns. His photo posts received more engagement than text or video, and his posts in the afternoon got more attention than those in the morning. This information helped him to strategize his campaign, focusing on sharing photo content in the afternoons for maximum engagement.
Henry’s adventure into metadata not only boosted his social media strategy but also secured him a victory in the student council elections. His deep dive into data about data had unlocked a new level of understanding, enabling him to connect with his fellow students more effectively. This is a testament to the power of metadata – it may not be the main character in our data story, but it sure does make a compelling supporting role!