Imagine you’ve just spent weeks, maybe even months, perfecting the most delectable, mouth-watering recipe for a chocolate cake. You’ve sourced the finest ingredients, tweaked measurements down to the last gram, and perfected the baking time to the second. Now, it’s time to serve it to your eagerly waiting guests.
But instead of a gleaming porcelain dish, you place this culinary masterpiece on an old, cracked plate that’s been gathering dust in the back of a cupboard. Worse yet, you decide to serve it using a flimsy plastic spatula that’s seen better days. The cake, though internally perfect, crumbles and falls apart, leaving both you and your guests disappointed.
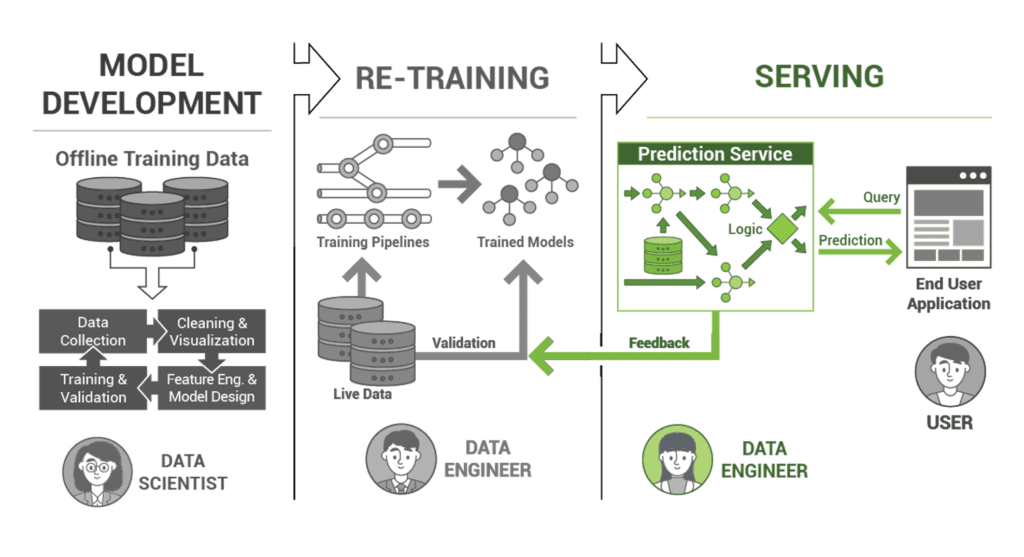
In the corporate world, developing a machine learning model is much like crafting that perfect cake recipe. After all the hard work, time, and resources invested into it, if you don’t have the right ‘serving layer’ – the mechanism to deliver the model’s predictions efficiently and accurately to the end-users or systems – then your masterpiece risks crumbling just like that cake. Developing and monitoring this serving layer is not merely about technicalities; it’s about ensuring the value you’ve created reaches your audience seamlessly.
The Silent Powerhouse: Developing and Monitoring the Serving Layer
Crafting an exceptional machine learning model is much like designing a supercar. You have the engine (your algorithm) tuned to perfection. But what good is an engine if it isn’t deployed correctly or if it can’t be driven on real roads (real-world data)? Enter the ‘serving layer,’ the unsung hero of the machine learning pipeline. Let’s dive into understanding why it is paramount to invest time and resources in developing and vigilantly monitoring this layer.
- The tip of the iceberg: Serving layer in action
The serving layer is the interface between our trained models and the real world. It’s where these models meet fresh, incoming data to make predictions or inferences. Think of it as the delivery system of your model. The effectiveness of this layer directly translates to the user experience. If it falters, the entire machinery feels the tremors. - Vigilance against model degradation
In an ever-changing world, our models can lose their edge over time. Imagine a weather prediction model trained on past decades of data. As global climates change, its predictions might become less accurate. Monitoring the serving layer can sound the alarms when the model’s assumptions waver or real-world data shifts, prompting timely interventions. - The need for speed: Scalability matters
Your model might start by serving a few users or systems. But as its popularity grows or as demands surge, the data floodgates open. A serving layer worth its salt won’t buckle under pressure. It scales horizontally, much like how a city expands its roads when traffic increases, ensuring that each request is processed efficiently, maintaining low latency. - Real-time matters in a real-time world
In today’s fast-paced digital age, waiting is passé. For applications like detecting potentially fraudulent transactions or suggesting the next song on a playlist, every millisecond counts. A robust serving layer ensures your models aren’t just accurate but swift, delivering predictions at the speed of thought. - Continuous learning: The cycle of improvement
The serving layer isn’t a ‘set it and forget it’ component. By meticulously monitoring its performance, we can catch issues before they balloon, refining our systems for ever-better performance. Consider it a feedback loop. If our real-world data starts to drift from our training data, this monitoring helps us catch the change, pointing towards recalibration. - Controlling quality: Ensuring reliability
The integrity of your machine learning system’s outcomes is often in the hands of the serving layer. Especially in applications where the stakes are sky-high – think medical diagnoses or autonomous vehicles – ensuring that the serving layer operates flawlessly is non-negotiable. By considering it as an equal partner in the ML pipeline, we cement the consistency and reliability of our outcomes.
Crafting the Perfect Serving Layer: Reliability, Performance, and Continuous Growth
In the dynamic tapestry of machine learning systems, every component plays a crucial role. But there’s one layer that is particularly pivotal, given its direct contact with end users: the serving layer. It’s akin to the waiter in a restaurant – no matter how good the chef, the waiter’s efficiency and presentation shape the dining experience.
1. The blueprint: Designing the serving layer
The serving layer’s design is crucial because it is responsible for supplying predicted outcomes or making inferences from the trained machine learning models. Every masterpiece starts with a vision, and the serving layer is no different. This layer deciphers the language of machine learning models and presents the insights, making it the face of your entire system. Consider how your users will fetch predictions. Whether it’s through an application, a web dashboard, or a simple API call, the user’s journey should be seamless. Anticipate growth! Design for surges in data or concurrent users. Ensure no downtime; after all, a closed restaurant serves no one.
- Modern architectures, like microservices, can be pivotal. Leveraging cloud platforms such as Amazon SageMaker or Google AI Platform offers flexibility, scalability, and a host of tools for efficient management.
2. Building blocks: Implementing the serving layer
Set up well-defined APIs for seamless and standardized interactions between the serving layer and other system components. Even the best models can sometimes trip. Ensure your system can handle unexpected hiccups gracefully, ensuring a smooth user experience.
- Using tools like Docker encapsulates your environment. This way, you’re assured that your model runs consistently regardless of where it’s deployed.
3. The watchtower: Monitoring the serving layer
Oversee, supervise, repeat. Constant monitoring guarantees that your serving layer is not just functional but optimal. Look beyond mere uptime; delve into accuracy and response times. Track system throughput, API response times, and the fidelity of your model’s predictions.
- Tools like New Relic or Dynatrace aren’t just monitoring tools; they’re your system’s health checkup. They provide crucial insights into system performance, ensuring you’re always ahead of any potential issues.
4. Evolution: Iterating based on feedback
Every system can be improved. Embrace growth. Use the insights gathered from monitoring to continually refine your serving layer. The restaurant that listens to its patrons’ feedback thrives. All issues aren’t created equal. Address critical bugs or bottlenecks that directly impact the user experience first. Your model isn’t static. Periodically refresh it with new data to keep it sharp.
- Adopt Agile methodologies to swiftly integrate improvements. Common techniques include Agile methodologies for Continuous Integration and Delivery (CI/CD). Visualization dashboards can be illuminating, highlighting areas of concern. Consider A/B testing to judiciously roll out enhancements, ensuring they truly benefit users.