Think about your morning coffee ritual. Now, you don’t just drink any coffee, do you? You probably have a specific brand, grind level, or flavor that you prefer. But let’s go one step deeper. That coffee you love so much starts with a particular blend of beans sourced from specific regions, harvested, and roasted under exact conditions. Each step is crucial to ensure that when you take that first sip in the morning, it’s perfect.
Just like that coffee, a machine learning system is only as good as its ingredients – the data it receives. And the vessel, the pathway through which this data travels and is processed? That’s the data layer. It ensures that when a machine learning system gets its ‘sip’ of data, it’s of the quality and precision needed to make accurate predictions and insights. And just as you wouldn’t want any impurities affecting the taste of your coffee, we don’t want any inconsistencies or inaccuracies in our data layer.
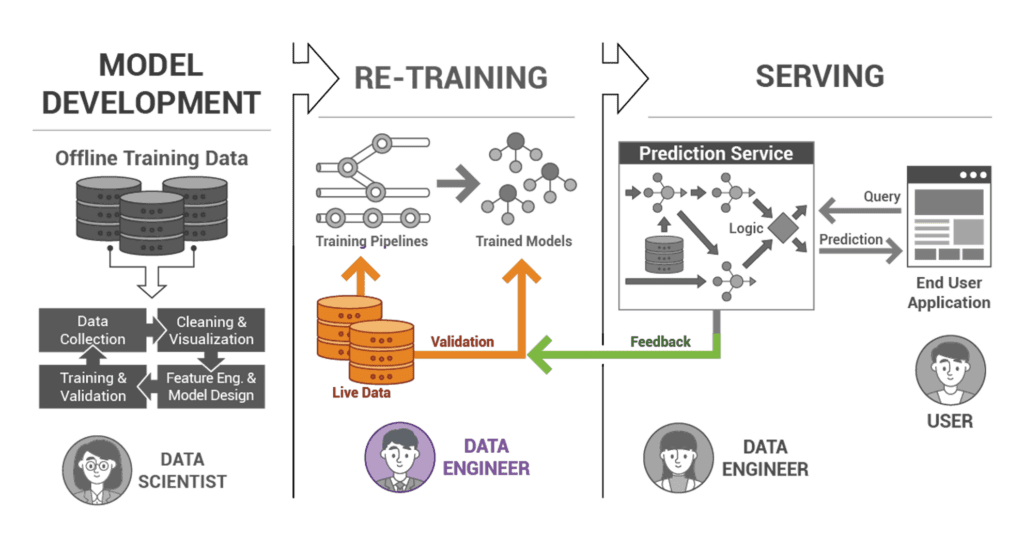
The Cornerstone of Machine Learning: Developing and Testing a Robust Data Layer
Imagine you’re building a skyscraper. The view from the top will be breathtaking, and its advanced design will surely captivate many. But this towering wonder begins with something far less glamorous yet critically important: its foundation. Without a strong base, even the most magnificent building can’t stand. In the realm of machine learning, data is that foundation and the data layer is its architectural blueprint.
Data is the foundation of machine learning models
Every machine learning model, whether predicting stock prices or detecting anomalies in medical images, thrives on data. But data isn’t static. As the world evolves, so does data. A robust data layer ensures that as new data emerges, our models remain informed, adaptable, and efficient. This layer is the unsung hero, constantly working behind the scenes, receiving raw data, refining it, and preparing it for the hungry machine learning models. It’s a dynamic storage and management system. Just as a small crack in a foundation can jeopardize an entire building, a flaw in the data layer can misguide a model, leading to inaccurate results and diminished trust.
Enhances data accuracy through feedback loops
We’ve all heard the saying, “Feedback is a gift.” In machine learning, it’s invaluable. Through feedback loops in the data layer, models get the necessary inputs to refine their predictions and learn from any mistakes, continually improving their accuracy.
Easy recovery and data versioning
Any experienced data scientist will tell you that data losses are nightmares. But a robust data layer, one that’s been tested thoroughly, acts as a safety net, ensuring that data is not only stored securely but can also be retrieved with ease. Think of it as a time machine. Different versions of datasets, stored systematically, mean that we can always revisit the past, understand historical model behaviors, and make informed decisions for the future. They allow for a greater understanding of the data a particular model version was trained or validated on.
Scalability
Just as cities evolve, expanding and housing more residents, machine learning applications also grow. A robust data layer is like the city’s infrastructure, ensuring that as the demand surges, everything runs smoothly. Whether it’s a sudden influx of user requests or an explosion in data volume, the data layer ensures no hiccups disrupt the model’s operations.
Consistent and seamless data flow
For a model to operate at its best, it needs a steady, uninterrupted stream of data. This consistency is assured by a well-tuned data layer, ensuring models aren’t left “starving” or “overwhelmed.” Inconsistencies can be the Achilles’ heel for machine learning projects. Any interruptions or inconsistencies in data flow can disrupt model training and performance. With a dedicated data layer, these are avoided, ensuring every model has the most accurate and relevant data at its disposal.
Enhances security measures
In an age where data breaches make headlines, the security of our data layer is paramount. It’s the guardian of our data, equipped with barriers, locks (access controls), and encryptions that keep intruders at bay. Just as we wouldn’t leave the foundation of a building exposed to threats, we ensure through rigorous testing that our data layer is armored against potential cyber-attacks.
Supports compliance requirements
Regulations aren’t mere paperwork; they’re a testament to the importance of data in today’s world. With a meticulously developed data layer, organizations not only ensure the best results from their machine learning models but also demonstrate their commitment to the highest standards of data handling and privacy.
Crafting a Data Layer: The Bedrock of a Machine Learning System
In the realm of machine learning, the data and its handling mechanism— the data layer — are of paramount importance. It’s crucial to ensure that the data layer is effective and optimized.
1. Implementation of the database
The database serves as the foundational storage for our data. We meticulously define tables and their relationships, mirroring the organization and categorization in a well-maintained storage system. For structured and well-defined data within a relational database, SQL databases with their relational architecture are the go-to choice. When the data is more fluid and varied, NoSQL databases offer the flexibility similar to an adaptable storage system. Ensures data flow includes automating the flow of data into and out of the database. This ensures that it’s always up-to-date and available for the pipeline.
The database is an active participant in the ML pipeline, ensuring data consistency between training and serving. As a result, it facilitates real-time predictions and enables continuous learning as new data flows in and the models evolve.
2. Test the data layer
Before deploying a system, it’s essential to test the data layer to ensure optimal performance during actual operations. This will help you identify and rectify any issues before deploying the machine learning system.
Types of Tests:
- Unit Tests: Write tests to ensure individual components (like data ingestion functions or transformation scripts) work as expected.
- Integration Tests: Ensure that the data layer integrates well with other components of the pipeline, such as preprocessing or model training modules.
- Data Quality Checks: Regularly check the data for missing values, outliers, or other inconsistencies.
- Load Testing: Simulate high volumes of data input and retrieval to ensure the data layer can handle peak loads.
Each module is tested on its own. And with the introduction of new data or system changes, retesting is a must.
3. Integration with the machine learning system
The importance of the data layer’s integration with the primary machine learning system cannot be overstated.
- Uniform Data Access: Implement a standardized data access layer or API to ensure consistent data retrieval and insertion across different stages of the pipeline.
- Data Connectors: Use tools and platforms that can automatically pull data from various sources like logs, streams, external databases, or APIs.
- Scheduled Ingestion: Set up automated jobs (using tools like Apache Airflow or cron) to periodically fetch and refresh the data.
- Data for Training and Validation: Automate the process of splitting data into training, validation, and test sets, ensuring consistent and reproducible model evaluations.
- Automate Transformations: Implement automated data cleaning, normalization, and transformation scripts or jobs.
- Feature Store: Consider setting up a feature store to manage, store, and retrieve preprocessed feature vectors for model training and inference.
The smooth coordination between the data layer and the primary system is vital. Integration tests act as a comprehensive check before full-scale deployment. Integration testing ensures that different components of the system work together properly.
4. Continual monitoring and updating
Once a system is in place, the work doesn’t end. It’s imperative to seek feedback, monitor data integrity, and innovate constantly based on the performance of the machine learning models. Using monitoring tools ensures that the quality and operations remain at their peak, much like a diligent supervisor ensuring flawless execution.
Foundations of a Robust Machine Learning Data Layer: Best Practices and Considerations
In the realm of machine learning, the data layer serves as the foundation upon which all other functionalities are built. Ensuring its robustness and efficiency is paramount. When developing and testing a data layer, there are several best practices to consider:
- Optimized data access
This involves designing efficient schemas and indexing strategies, ensuring that data can be accessed swiftly and without hiccups. Additionally, for data that’s frequently accessed, implementing caching solutions can significantly reduce the load on the database, ensuring smoother operations.
- Monitoring and logging
Real-time monitoring tools can provide invaluable insights into the health, performance, and resource utilization of the database. This proactive approach helps in identifying and rectifying potential issues before they escalate.
- Accuracy and efficiency in data
It’s vital to regularly scrutinize the data for any anomalies, outliers, missing values, or inconsistencies. Automated validation checks during data ingestion can be a game-changer, ensuring that the data layer remains pristine. Furthermore, testing the database’s performance under varying loads ensures that it consistently meets the required latency and throughput benchmarks.
- Integration testing
Every time there’s an update or change, it’s crucial to test the entire flow, from data ingestion to model training, ensuring seamless operations. Integrating data layer tests into the Continuous Integration process ensures that any change to the data layer or its related components undergoes rigorous automated tests, guaranteeing that everything functions as expected.
Navigating the Pitfalls: Challenges in Data Layer Development and Testing for Machine Learning
Building the data layer is a crucial step that requires careful preparation and attention to detail. A data scientist must anticipate and navigate the challenges that arise during the development and testing phase of the data layer.
Let’s delve into some of the potential issues and challenges one might encounter.
Inadequate data cleaning
Training a model on unclean data can result in unsatisfactory outcomes. The consequences are inaccurate and inefficient models that could render the model performance poor. Trust erodes as stakeholders notice discrepancies. Sometimes, even the most diligent professionals underestimate the complexity of the task. The cause of this mistake is usually a lack of strong knowledge in data preprocessing. Data scientists might overlook the importance of cleaning up data before feeding it to the model.
- Imagine an online shoe store’s AI recommending winter boots for a beach vacation simply because of uncleaned redundant entries. Frustrating, right? Just as a chef meticulously selects and cleans ingredients, a data scientist should invest time and leverage tools like Pandas and NumPy (in Python) for data cleaning, ensuring the base is robust before model training begins.
Ignoring data privacy
A secret whispered, only to be overheard by unintended ears. This is how users feel when their data is mishandled. Breaching trust can lead to irreparable damage, both legally and reputationally. It’s not just about a tarnished image; it can threaten the very survival of an organization or system. In the race to harness data, developers sometimes overlook or underestimate the sanctity of personal information. Data might be collected indiscriminately without a full understanding of its implications.
- Consider a health app promising to track your fitness, but it secretly gathers personal messages or photos. Such betrayals not only result in legal ramifications but also alienate users, leading to plummeting trust and credibility. The path forward is clear – prioritizing user privacy is paramount. Implementing stringent data policies, seeking explicit consent, and ensuring data anonymization are not just best practices, they’re essential. Transparency is the key to maintaining trust.