 QuantHub Learning 101 is a series that explores the learning science behind what makes our product effective. This post discusses spaced repetition learning as the solution to the forgetting curve. Or, in plain language, we discuss in this post how to stop forgetting important information!
QuantHub Learning 101 is a series that explores the learning science behind what makes our product effective. This post discusses spaced repetition learning as the solution to the forgetting curve. Or, in plain language, we discuss in this post how to stop forgetting important information!
Recently, I was asked to recall my best and worst training experiences. I was a little embarrassed with how long I grappled with answering the question. I’ve been to hundreds of trainings at this point in my professional career, yet I could not recall a single one without a considerable amount of effort. Finally, I landed on the best (well, most memorable) experience, a training on gang violence and affiliation that I took while I was working with the Department of Juvenile Justice. The worst was an amalgamation of so many eLearning trainings that have been compulsory boxes to check. This reflective exercise was both enlightening and depressing.
How many of your past trainings do you remember? Could you recall what you learned from many of them, or would the most lasting memory be what food they served?
An individual can learn virtually anything at any time. Is that time to learn really well-spent if it is just forgotten in a matter of weeks or sometimes even minutes? This is a question organizations are asking constantly as they struggle to close critical skills gaps.
Is learning and development a strategic investment if employees aren’t really retaining, and even more importantly, applying what they’ve learned?
Training Budgets under Pressure
The average organization spends 2-2.5% of their annual budget on training. That amounts to a little over $808,000 for mid-sized companies. For companies trying to squeeze every ounce of value out of their budget, investments in employee training cannot mean unrealized value added. Companies have to consider not only the cost of training but the cost of employee’s time. Lost revenue per hour of employee training can be a tough pill to swallow; however, well-planned and executed training can have exponential return on investment. In the case of data literacy, companies can expect to increase their market cap by up to 5% with implementing a data-driven decision making. A little harder to quantify, yet just as important, is the opportunity for training to increase employee retention, productivity, and engagement. Companies have a real opportunity to invest their learning and development budgets wisely in order to realize significant gains. There is also a substantial risk with learning and development. Companies know that training that is not immediately useful and quickly forgotten is money wasted. A 2020 Training Industry Report indicated that among companies’ highest priorities are increasing training effectiveness, reducing costs, and improving efficiency.
Increasing training effectiveness is especially a problem when the training you are developing for your organization is not just for skills, but for a mindset. This is the case for key stakeholders charged with creating an organization-wide adoption of data literacy, an understanding of data that not only allows employees to use it effectively but for it to be an integral and pervasive part of their processes and decisions. We are seeing organizations large and small who are faced with a similar problem, how do we train employees in differing roles in such a way as to not only LEARN and RETAIN data but also THINK data? In fact, one of our partners, Blue Cross Blue Shield of North Carolina has gone so far as to make “Think Data” one of their core values. In order to realize the well-documented benefits of being data-driven, it is not enough for an organization to simply HAVE data. It’s what you do with data that counts.
Learning and development teams are faced with a colossal problem: to develop a training solution that spans beyond learning a specific platform or task. In one approach, they may choose to develop and curate a series of long-form trainings. Each one covering a topic that seems necessary for the participants. The problem is individuals are s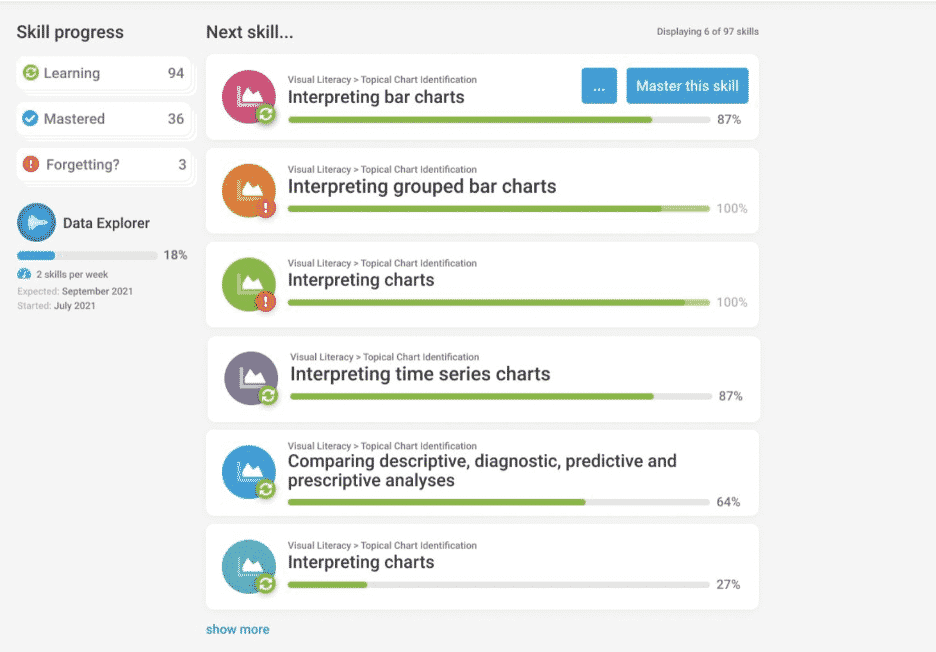 tatistically likely to forget the content within a matter of weeks, rendering the possibility of imparting a lasting mindset shift impossible.
tatistically likely to forget the content within a matter of weeks, rendering the possibility of imparting a lasting mindset shift impossible.
The Forgetting Curve
Turns out, there’s a science to why we can’t remember things we recently learned. One-time learning is often ineffective because of a concept called the Forgetting Curve. German Psychologist Herman Ebbinhaus discovered that learned information is forgotten along a somewhat predictable time constant called, “decay.”
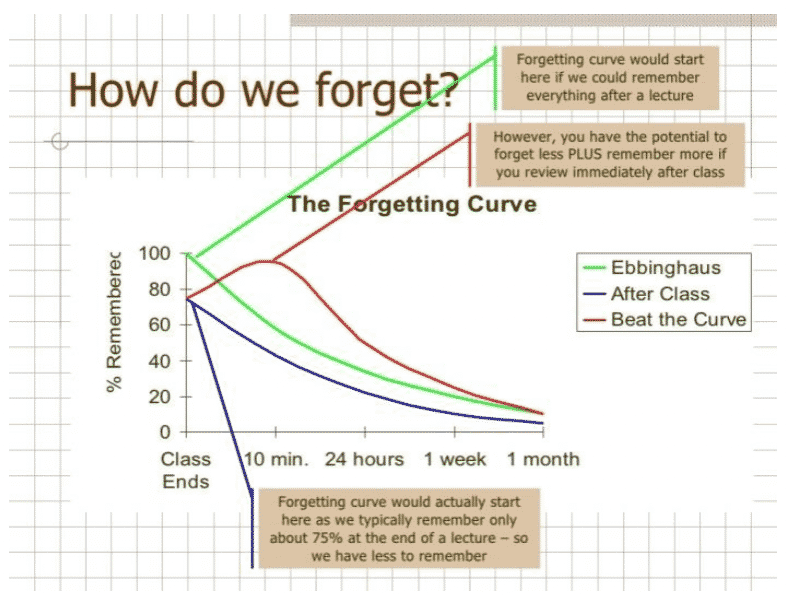
Source: Stanislaus State
Ebinhaus’ hypothesis was again confirmed by a study in 2015. The study found learners forget between 60 and 75% of material in a matter of minutes with a continued decline over a month. The end result is remembering only about 10% of what was learned. Memory retention is a significant problem for individuals and companies alike. Companies weighing their options for increasing training effectiveness are trying to figure out how to recapture at least a portion of that lost 90% of training.
QuantHub’s solution to this problem was the use of artificial intelligence and the method spaced repetition in order to minimize information being forgotten. Spaced repetition has been so well-studied by cognitive scientists that the methodology has become more accepted for not only its benefits for learners’ ability to actively recall information but also their memory on the whole (Kang, 2016). Up for debate is the optimization of when review of material should actually occur. Other factors influence individual’s ability to recall information such as previous knowledge or contextualization of the material.
QuantHub utilizes a public domain library called Ebisu that employs a powerful model predicting when learned content will be forgotten. The forgetting curve provides insights on when a review of material is best to combat the natural decay of memories; however, without adaptive machine learning, spaced reviews are not optimized. Generally, spaced review of content can take place in the following intervals:
- Immediately after information is learned
- Again, within about a week
- And a few more times a month to two months out.
Each time the information is reviewed, the amount of time needed for a review is less.
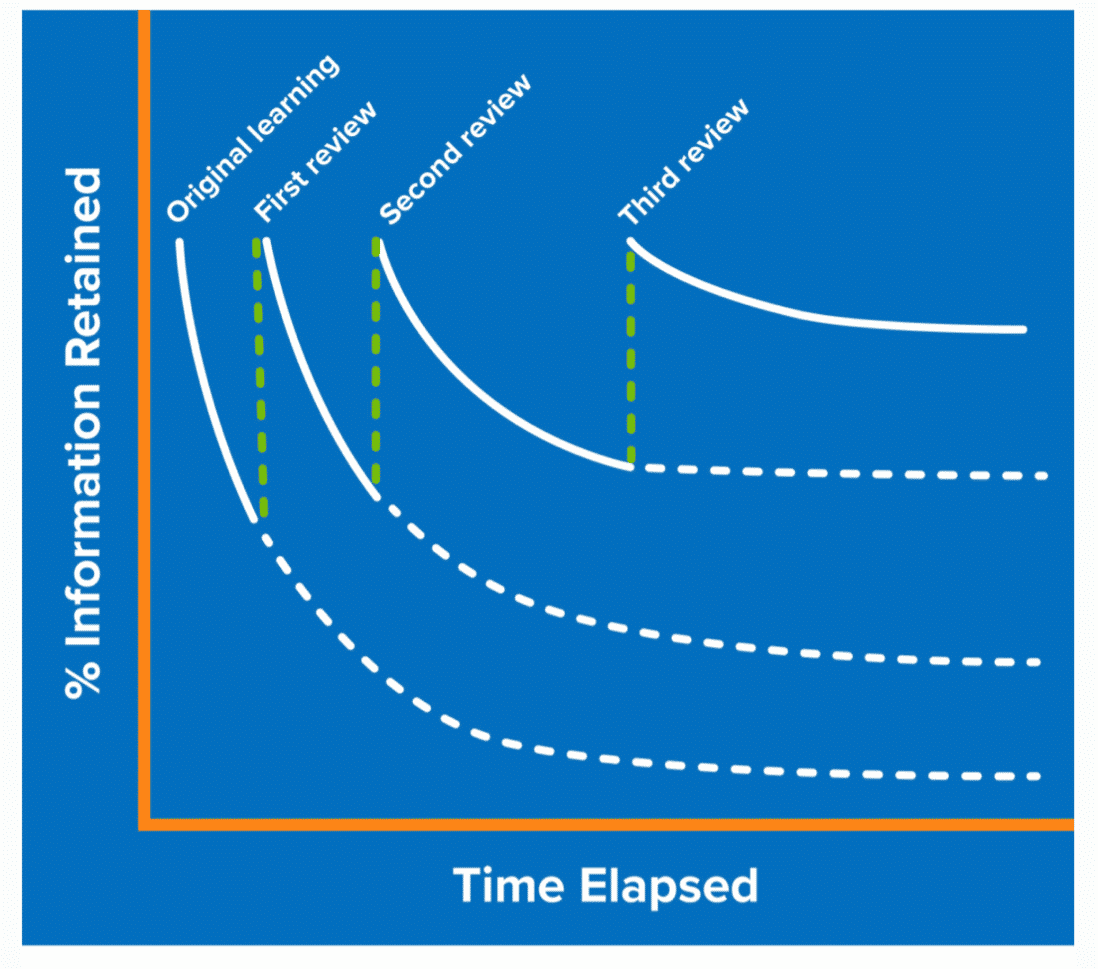
Source: MindTools
A person’s likelihood of remembering a given piece of information is called their recall probability. The recall probability answers the questions “Which facts need reviewing?” and “How does the student’s performance on a review change the fact’s future review schedule?” That second question is where the real machine learning magic happens. Based on a learner’s responses to each question, we are able to predict:
- What learners may be ready to learn next.
- What they need to review.
- A scheduled learning path that adjusts according to every single question a person answers.
Item recall probabilities and the schedule of review items change with each interaction a learner has with the learning activity. Machine learning adapting to human variance curates a truly unique and optimized learning experience!
The Spaced Repetition Algorithm
QuantHub’s spaced repetition algorithms are also heavily influenced by Anki, an open-source Python flashcard app. Anki was designed for individuals learning large amounts of information. Learners essentially have three categories of information: New, Learning, and To Review. One study comparing medical students using Anki to those who did not found that Anki users perform better on medical examinations.
The language learning platform, Duolingo, uses a very similar technique to gauge a person’s strength in a specific skill, and therefore, their need in reviewing as well as their readiness for more difficulty. They call their combination of machine learning and elements of the forgetting curve a Half-life Regression. In their blog article, How we learn how you learn, they reveal that this algorithmic approach to learning has the lowest mean absolute error in its ability to predict what your will forget. Not only that, but A/B testing revealed that learner retention was significantly higher with this method with a 12% increase in learner activity.
This is why spaced repetition is important.
How does QuantHub work in this Learning Framework?
Learners on the QuantHub Upskill Journey begin at the same point; however, every step that follows will be unique to their personal reference knowledge, context, learning speed, cognitive load, etc. Every learner has a whole host of differences that affect their own forgetting curve. Machine learning allows for the concept of the forgetting curve to be adapted to everyone’s unique learning situation.
A learner begins as a Data Citizen on our platform. If they answer a question correctly, they signal that they are ready for a more difficult challenge and that their timeline for review on that particular skill could be adjusted to allow for a longer gap before a review is needed. The algorithm accounts for a learner’s skills strength which informs subsequent question selection as well as length of time needed for additional practice. Each correct answer helps you to make progress toward mastery of the skill. Once a skill is mastered, the algorithm predicts when you will begin forgetting the skill, prompting you to quickly review the skill at the best moment to avoid forgetting.
Similarly, an incorrect response demonstrates a lesser strength in a given skill. Learners are prompted to review a related resource for an immediate review of the concept, and the learner’s recommended path is adjusted to accommodate more review time for this skill at an earlier time.

Learners who are proficient in many of the lower-level skills quickly review the fundamentals while the algorithm adjusts their review timelines so that they can rapidly tackle more difficult skillsets. Conversely, learners with little to no previous instruction are given the time and necessary practice to truly gain the skills they need.
Each practice session improves the accuracy of the learner’s recommended learning path as well as the metric for the learner’s skill strength.
Companies simply cannot afford to let their training budgets go to waste. And employees cannot afford to spend time on training that isn’t useful or memorable. QuantHub has harnessed the power of machine learning to optimize human learning. Using QuantHub for data literacy upskilling ensures that your training budget is well-spent.
Get started using spaced repetition practices in your data skills lessons – find out more about our upskill accounts here!